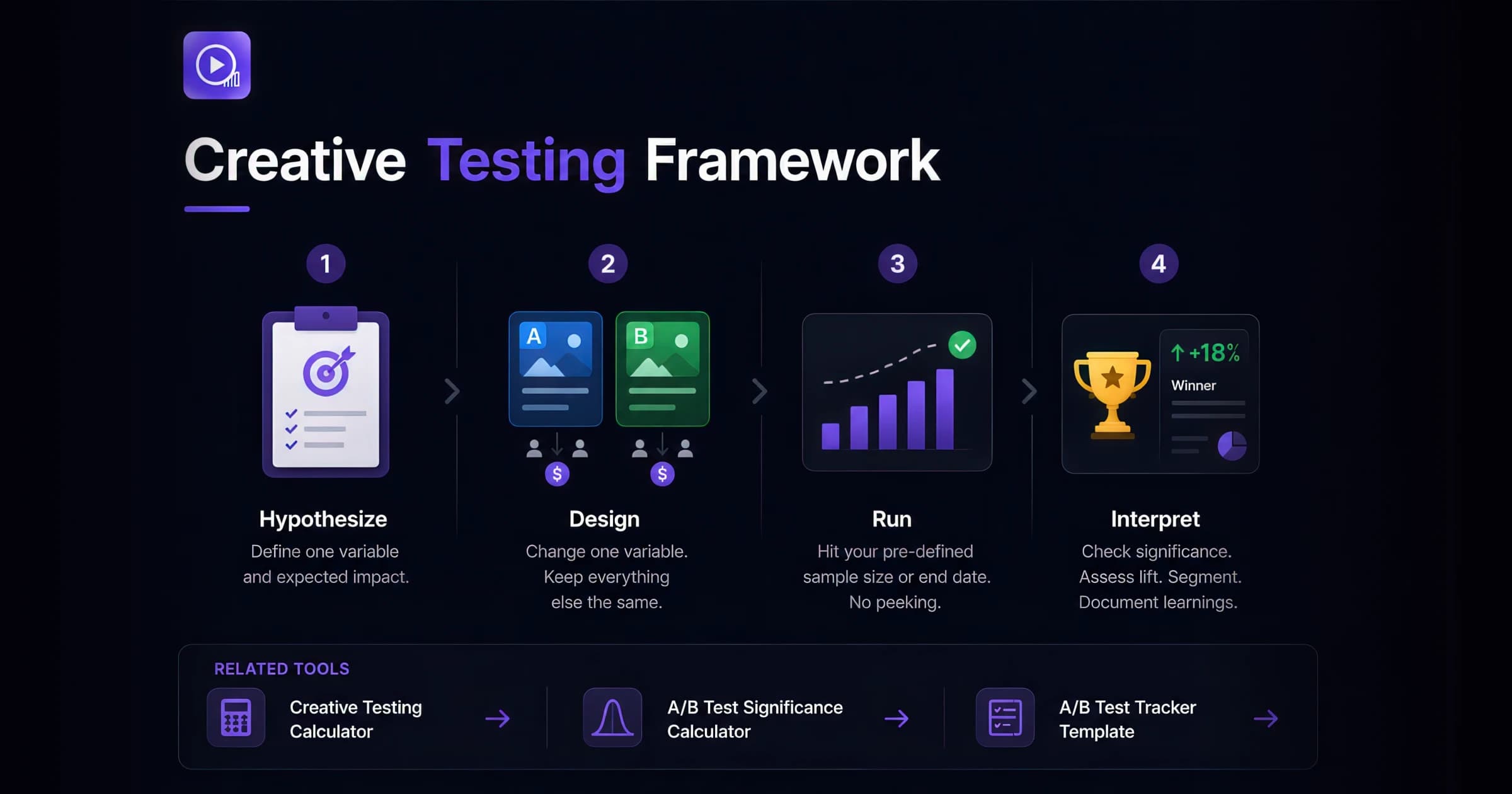
Most "winning" tests are not. The fastest way to ship false winners is to read results before a test has gathered enough data, to call any difference a result, or to confuse a metric that moved in-platform with revenue that actually grew. Trustworthy experimentation is the discipline of separating signal from noise — and it rests on three dials you set before the test starts, not after.
The first dial is statistical significance, usually expressed as 95% confidence (p < 0.05). It answers a narrow question: if there were truly no difference between A and B, how often would random chance alone produce a gap this large? It does not tell you the variant is better, by how much, or whether the difference matters to the business. The second dial is statistical power, conventionally 80% — the chance your test detects a real effect that exists. Underpowered tests are the silent killer: they quietly miss real wins and leave teams concluding "no difference" when there was one.
The third dial is sample size, and it is driven by your baseline conversion rate and the minimum detectable effect (MDE) you care about. Lower baselines and smaller effects both demand dramatically more traffic. As concrete anchors at 95% confidence and 80% power, a 5% baseline rate needs roughly 31,000 visitors per variant to detect a +10% relative lift, or about 8,100 to detect a +20% lift; a 1% baseline needs roughly 163,000 per variant for a +10% lift. Fix the sample size in advance, then resist peeking — checking repeatedly and stopping the moment you see significance inflates the false-positive rate far above the 5% you think you set.
Finally, a significant in-platform lift is not the same as incremental revenue. Platform attribution credits conversions that often would have happened anyway; the only way to know what your marketing truly caused is a holdout or geo experiment that compares an exposed group to an unexposed control. Use the calculators below to plan sample size and read significance, the glossary to ground the concepts, and incrementality testing to confirm that a statistically real lift is also a real business one.