Stay Updated
Get the latest insights on creative testing and ad optimization delivered to your inbox.
Get the latest insights on creative testing and ad optimization delivered to your inbox.

Continue reading about this topic with these recommended articles.

Andromeda rebuilt the retrieval stage of Meta's ads delivery; GEM and the Adaptive Ranking Model rebuilt ranking. Here is what actually changes for an operator: what to feed the system, how to structure the account, and how to run creative rotation — with every platform claim cited to Meta's own disclosures.
AI-powered marketing tools
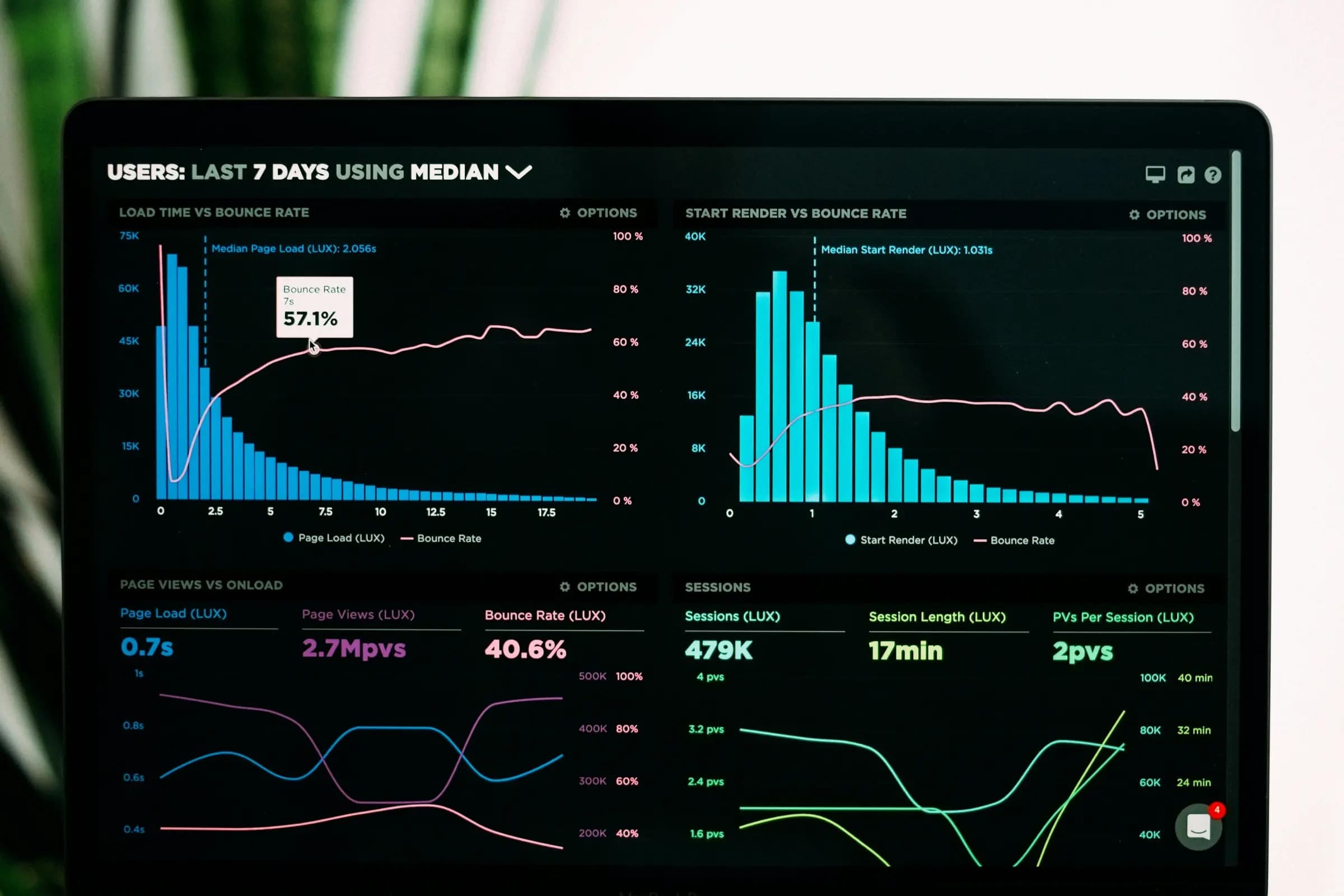
Learn how to transform raw advertising metrics into actionable creative insights through data storytelling and interpretation. Master the art of deriving meaningful narratives from campaign data.
AI-powered marketing tools
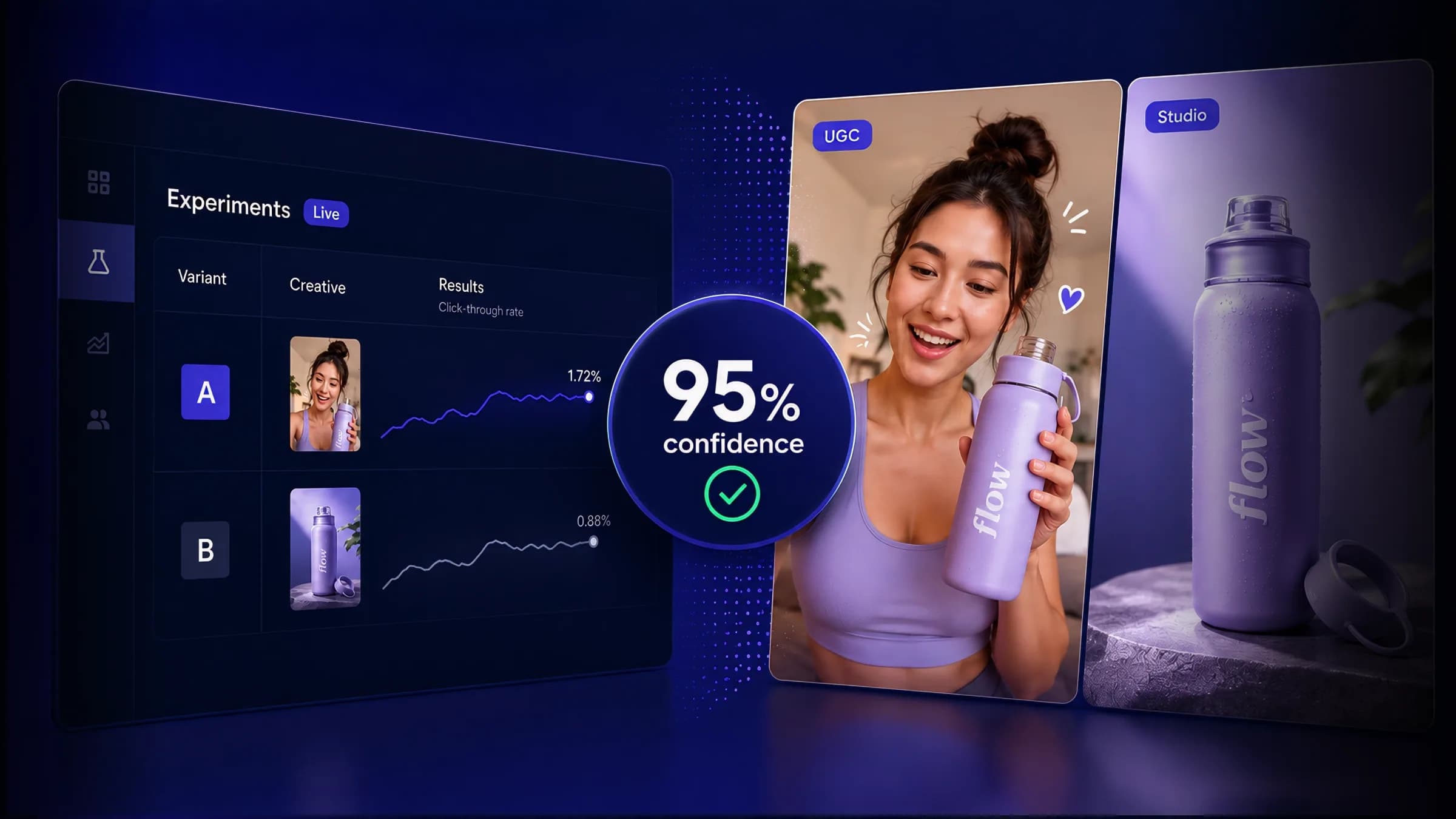
Most Meta creative tests declare false winners. This playbook covers hypothesis design, Meta Experiments setup, sample-size math, and the three-metric read that separates signal from noise.
AI-powered marketing tools

Grade your ad creatives and get actionable recommendations for improvement. This creative quality grader tool evaluates key elements like visual design, messaging, CTAs, accessibility, and platform optimization to help you create high-performing ads across Facebook, Instagram, TikTok, and YouTube. Get detailed scores and personalized tips to optimize your creative strategy.

Maximize your customer relationships with our comprehensive LTV calculator. Analyze customer value over time, identify growth opportunities, and develop data-driven strategies to improve retention and revenue per customer.

Analyze audience drop-off and retention to find exactly where viewers stop watching your videos. Works for YouTube, Vimeo, TikTok, and Facebook analytics data.
Creative optimization is a systematic, data-driven process of analyzing and improving ad creative elements to enhance key performance metrics like CTR, conversion rate, and ROAS. It combines creative testing insights, performance data analysis, and iterative refinement to continuously improve creative effectiveness. The process includes establishing baseline performance, identifying test opportunities, implementing controlled experiments, and scaling successful variations.
Creative analysis is the process of assessing ad creative performance by examining metrics like CTR, conversion rate, and engagement. This analysis helps identify which creative elements resonate with audiences and inform future creative strategy.
Social proof is a fundamental psychological principle where individuals determine appropriate behavior and decisions by observing the actions, experiences, and validation of others. In marketing and advertising, it manifests through multiple forms of evidence demonstrating widespread acceptance or success of a product, service, or brand. This includes verified customer reviews, detailed testimonials, transparent usage statistics, credible expert endorsements, recognized certifications, and measurable social signals. The principle operates on the documented observation that people rely heavily on others' experiences to assess value and trustworthiness.
A value proposition is a clear articulation of the tangible results a customer gets from using a product or service. It focuses on the specific problems solved, benefits delivered, and unique advantages offered compared to alternatives. An effective value proposition demonstrates deep understanding of customer needs while differentiating the offering in meaningful ways that resonate with the target audience.
As Meta automates audience, placement, budget, and creative optimization, the hunt for a single winning ad is a weaker scientific unit. The better question is which creative features—hooks, proof, messengers, contexts—compound signal across delivery environments.
For years, performance teams organized creative decisions around a deceptively simple objective: find the winning ad, put budget behind it, then repeat.
That logic always had cracks. In 2026 those cracks are a structural problem.
Meta has moved more of the workflow into automated systems. Engineering disclosures describe stacks built for retrieval, ranking, and personalization—systems designed to evaluate large candidate sets, fuse heterogeneous signals, and make context-specific decisions in real time. Reuters has also reported a roadmap toward more fully AI-generated and AI-targeted advertising workflows.
This article makes that case in four moves:
The phrase “winning ad” sounds precise. Analytically, it is vague.
An ad is a bundle—often simultaneously:
When Ad B beats Ad A, teams often behave as if they learned one clean lesson. More often they observed a noisy composite of many co-occurring variables—exactly the failure mode we described when marketers over-read single observations and move from outcome to explanation too quickly.
The chart above is a toy model, but the lesson transfers: smoothing and repetition help you avoid mistaking volatility for truth. That is necessary—but not sufficient—when the “signal” you care about is not the ad curve itself, but the repeatable creative ingredients inside it.
Two things are true at once.
First, the system is getting better at matching ads to contexts. That can lift outcomes.
Second, the performance of any individual ad is increasingly contingent on a richer optimization environment than many teams intuitively model. When someone says “Ad B beat Ad A,” a more honest translation is:
That is weaker than “this concept is better.” Once you admit the gap, the operative question becomes: what inside the ad produces repeatable lift even as routing changes? That question is closer to the real job of a serious creative organization.
Winner worship is not only epistemically sloppy. It trains teams to learn at the wrong level of abstraction.
Same weekly output can compound knowledge—or compound imitation.
Clone the top ad. Brief “something like this one.” Treat fatigue as asset death instead of pattern saturation. Refresh surface execution while keeping the same claim architecture.
Typical outcome
Busy output, shallow learning, and a library of near-duplicates.
If the ad is too bundled to be the best analytical atom, the right middle ground is the creative feature: a component large enough to matter strategically, but specific enough to tag and test across assets.
Pain-led open, curiosity gap, direct claim, social proof, contrarian take, founder story, visual disruption, identity mirror.
Speed, savings, status, comfort, simplicity, certainty, transformation, risk reduction—what is the primary promise architecture?
This is where creative diversification stops being only a production philosophy and becomes a measurement system: if creative carries targeting information, that information should be labeled, stored, and evaluated—not only improvised on set.
Consider four Meta ads for the same SKU. The point is not the fictional numbers—it is the inference jump.
If those questions sound expensive, compare them to the cost of a quarter spent confidently building the wrong pattern.
A specific ad is fragile: novelty, edit, seasonality, auction pressure, and creative fatigue all attach to the bundle first.
For time-series discipline on decay versus noise, our creative fatigue walkthrough emphasizes moving averages and structured detection—not daily panic[7]. Even when decay is real, what often decays first is a pattern of message, proof, or context—not “the mp4” as an abstract object.
That is why feature models travel: you can change surface execution while preserving ingredients that still work—or demote a proof mechanism that saturated while the value proposition remains sound.
Strategically meaningful and realistically repeatable tags—deep enough to explain, shallow enough to use weekly.
A feature earns status by recurring across assets with directional outcome relationships—not one heroic outlier.
Some hooks earn their keep on attention; some proofs earn it on conversion. Do not flatten the funnel into one scoreboard.
Expert validation may rescue a bold claim; generic UGC may not. Impulse categories are not high-consideration categories.
When volume explodes—especially with generative workflows—interpretive discipline becomes the bottleneck. More ads without a hypothesis structure does not increase learning; it industrializes confusion unless you know what you are trying to isolate[2].
The “winning ad” is not entirely gone. Budget still flows to assets. Some executions deserve iteration; others deserve retirement.
But as a mental model, asset-level winner worship is increasingly misaligned with how large platforms optimize delivery—and it systematically under-invests in the layer where durable strategy actually lives.
The more useful center of gravity is feature-level learning: harder questions, smarter tagging, resistance to instant grand theories, and a measurement stack that tells you not only what won last week, but what is likely to work again.
Not a gallery of winners. A model of reality.
This essay is the measurement half of the argument. The operational half — what to change in the account itself now that retrieval and ranking run on the AI stack described above (concept diversity, consolidated structure, rotation cadence) — is covered in the Meta Andromeda operational playbook.
For teams scaling variant throughput with agentic workflows — Remotion renders orchestrated by Claude Code skills — see Agentic Video Ads with Claude Code.

AdSights has long argued that creative is the new targeting—creative encodes who should see the message when explicit controls thin out[1]. If that is true, then creative analysis cannot stop at the asset level. It has to move down to the feature level.
Winner declarations often collapse many co-moving creative choices into one headline.
Delivery is increasingly downstream of ranking, retrieval, and budget systems—not a clean A/B Petri dish.
Hooks, proof, messengers, and contexts can recur across assets and be tested with intent.
Taxonomy, repeatability, metric layering, interactions, and time—not another leaderboard.

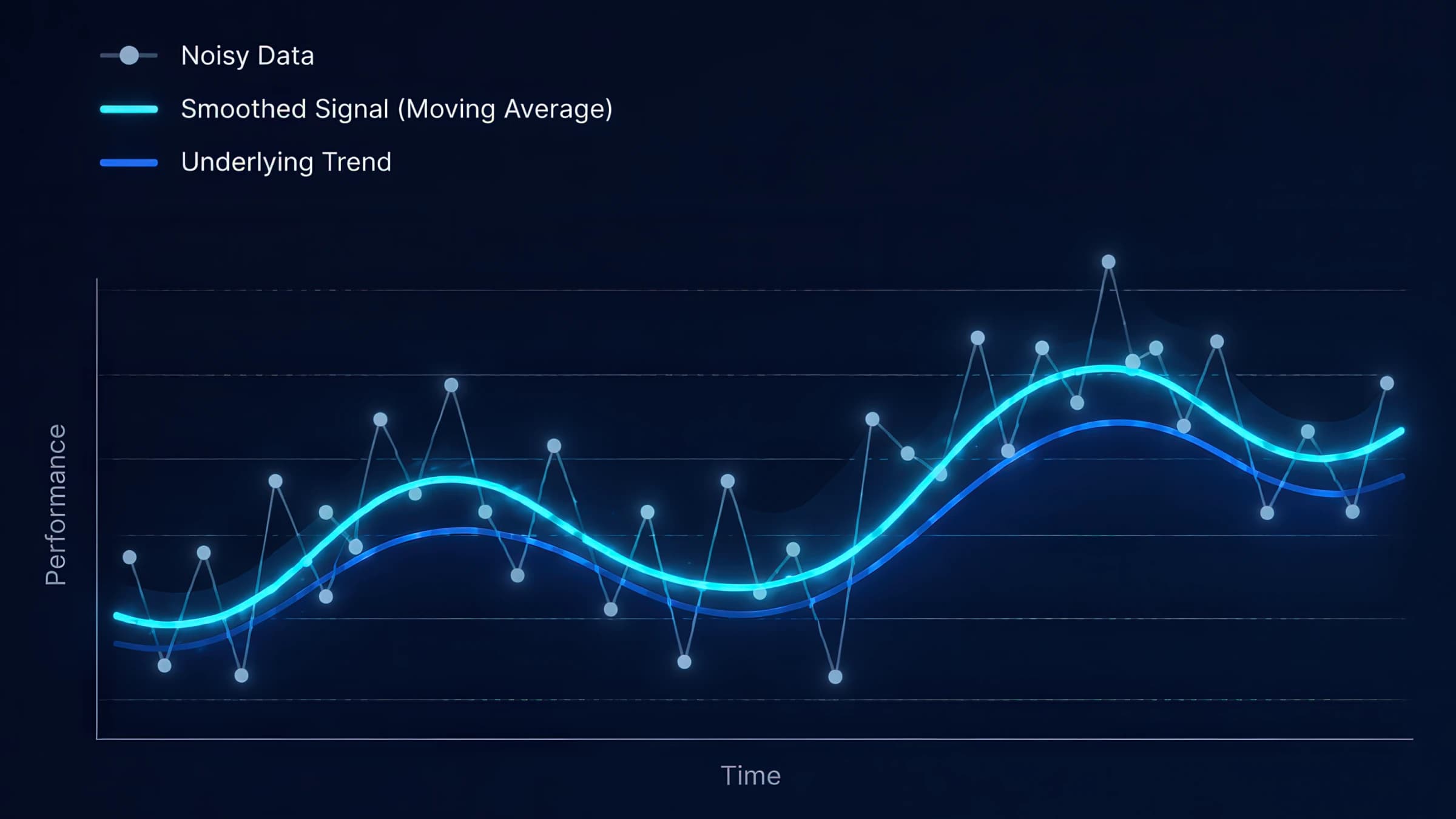
This data shows how underlying signals can be obscured by noise. The moving average helps identify the true pattern beneath random fluctuations. Interactive controls allow adjusting signal-to-noise ratio and smoothing parameters.
| Point | Noisy Data | 10-pt Moving Average |
|---|---|---|
| 1 | 3.22 | 3.22 |
| 2 | 3.07 | 3.15 |
| 3 | 6.48 | 4.26 |
| 4 | 6.62 | 4.85 |
| 5 | 6.14 | 5.11 |
| 6 | 5.68 | 5.20 |
| 7 | 5.87 | 5.30 |
| 8 | 5.19 | 5.28 |
| 9 | 6.20 | 5.39 |
| 10 | 7.20 | 5.57 |
| 11 | 5.83 | 5.83 |
| 12 | 5.08 | 6.03 |
| 13 | 7.07 | 6.09 |
| 14 | 6.77 | 6.10 |
| 15 | 5.49 | 6.04 |
| 16 | 5.69 | 6.04 |
| 17 | 5.42 | 5.99 |
| 18 | 6.15 | 6.09 |
| 19 | 5.41 | 6.01 |
| 20 | 7.58 | 6.05 |
| 21 | 5.46 | 6.01 |
| 22 | 7.00 | 6.20 |
| 23 | 4.84 | 5.98 |
| 24 | 3.88 | 5.69 |
Sample of simulated daily values: a relatively stable creative-feature index, a noisier bundled-ad read, and a short moving average of the ad read. Enable JavaScript for the full chart.
| Day | Feature index | Bundled ad | 5-day MA |
|---|---|---|---|
| 1 | 0.620 | 0.672 | 0.672 |
| 2 | 0.638 | 0.738 | 0.705 |
| 3 | 0.653 | 0.820 | 0.743 |
| 4 | 0.663 | 0.679 | 0.727 |
| 5 | 0.669 | 0.578 | 0.697 |
| 6 | 0.669 | 0.577 | 0.678 |
| 7 | 0.667 | 0.627 | 0.656 |
| 8 | 0.665 | 0.680 | 0.628 |
| 9 | 0.664 | 0.763 | 0.645 |
| 10 | 0.665 | 0.782 | 0.686 |
| 11 | 0.669 | 0.775 | 0.725 |
| 12 | 0.675 | 0.679 | 0.736 |

Under the platform’s current delivery logic, for the mix of users and contexts it surfaced, with the model’s current understanding of relevance and value, this bundled creative package produced better aggregate outcomes over some window.

If you cannot name what you changed between variants, you should not be surprised when the platform cannot “learn” what you learned either—because even you did not encode it.


Ad | Hook | Proof | Messenger | Context | CTR | CVR |
|---|---|---|---|---|---|---|
| A | Direct problem | Demo | Founder | Morning routine | Strong | Avg |

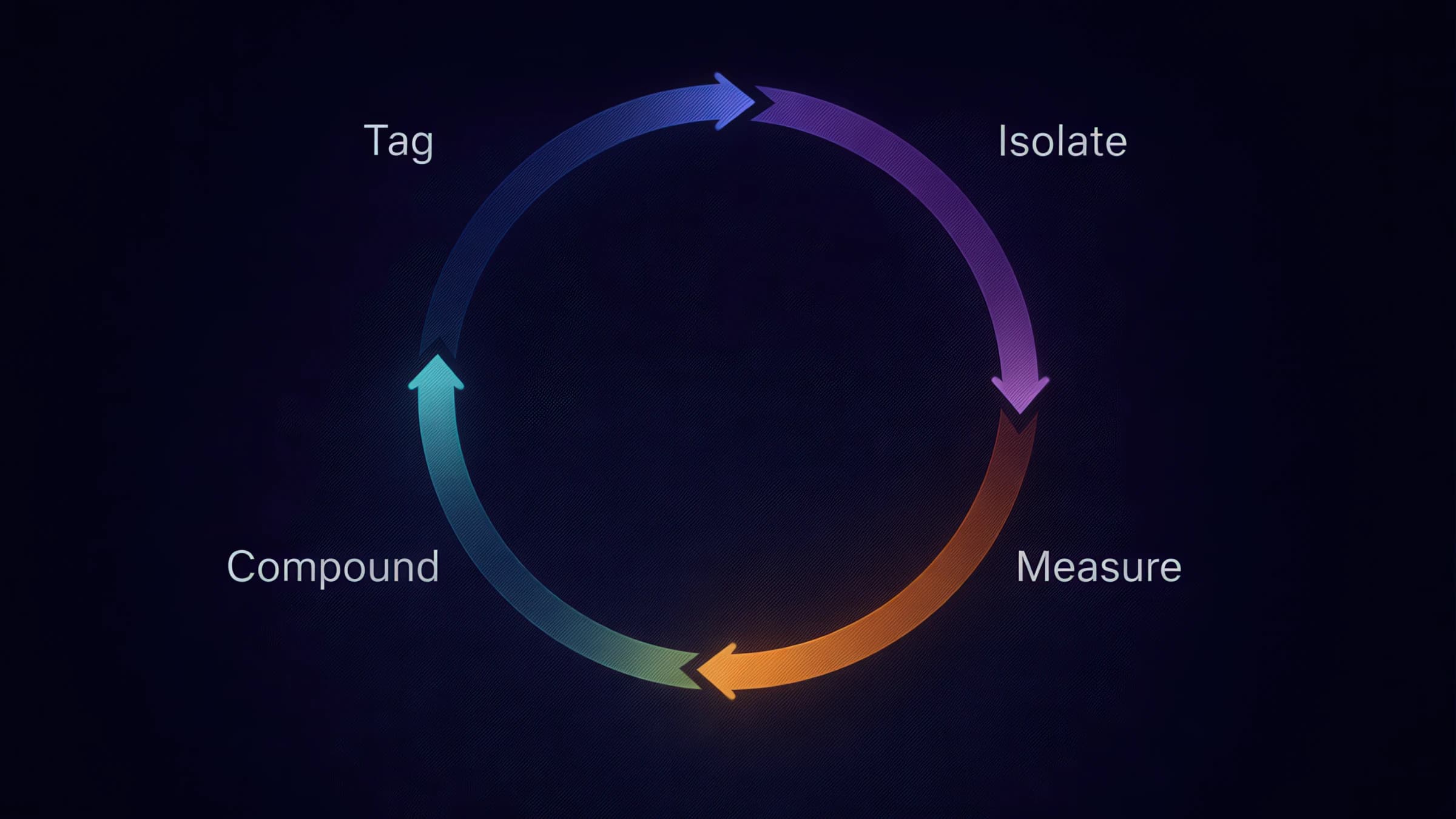
A practical sequencing loop for teams moving beyond asset roulette
Encode the bundle
Design contrasts
Layer KPIs
Update the model
Use the alongside when you are sizing whether a feature contrast has enough volume to support a decision.

Tag hooks and proof consistently. Design tests to separate messenger from mechanism. Retire combinations, not ingredients, when performance decays.
Typical outcome
An accumulating model of what your market rewards across contexts.
Testimonial, demonstration, comparison, quantified outcome, before/after, expert validation, authority cues.
Who speaks, where the product lives narratively (morning routine, work stress, parenting moment, social moment), and how quickly the product appears.
| B |
| Curiosity |
| Testimonial |
| Customer |
| Morning routine |
| Avg |
| Strong |
| C | Direct problem | Testimonial | Customer | Workday stress | Strong | Strong |
| D | Authority claim | Demo | Founder | Workday stress | Weak | Weak |
Treat feature performance as a living distribution: robust, fragile, rising, saturating, or context-bound.
Conclusion
Ad C wins.
Next step
“Make more ads like C.”
You store one asset-level lesson. When C fatigues, the team panics—because the lesson was never decomposed into reusable parts.
Better questions